Unstructured data is all around us (emails, log files, facebook posts, twitter statuses) yet it’s difficult to analyse. HP has a product that does some common analysis tasks for you. It’s called IDOL (Intelligent Data Operating Layer) and comes with an easy to call web API (IDOL OnDemand https://www.idolondemand.com). In this post I’m going to look at how to call a few of the text analysis endpoints from a Java program.
Insightful tweets
Companies need to understand how their product is viewed and a useful way of discovering this is analyse posts on social media. We can get a rough measure of whether a user thinks positively or negatively about it by performing sentiment analysis on the post. So, let’s build an application that looks at tweets on a given subject and displays the sentiment along with some other information.
Endpoints
The three endpoints we will use are
Calling from Java
The endpoints are called using one http GET with parameters attached. Here’s how we do this in Java.
First we create the URL. Let’s take the sentiment analysis call as an example. The three things that we need to provide (as shown by the documentation) are
- API key (your personal identifier)
- The text to analyse
- The language of the text
We create a request object
public class SentimentAnalysisRequest {
private static final String REQUEST_STRING = "detectsentiment";
private static final String VERSION_STRING = "v1";
private final ProcessRequestType type;
private final String identifier;
private final SentimentLanguage language;
public SentimentAnalysisRequest(ProcessRequestType type, String identifier, SentimentLanguage language) {
this.identifier = identifier;
this.type = type;
this.language = language;
}
public String toUrlComponent(){
return REQUEST_STRING+ "/" + VERSION_STRING + "?" + type.urlSegment + "="+ UrlUtils.urlEncode(identifier)
+ (language==null? "" : "&language="+language.name());
}
public enum SentimentLanguage {
ENG,FRE,SPA,GER,ITA,CHI
}
}
and collapse it to a URL string (toUrlComponent). One thing to notice here is that we need to encode the text to analyse so that we can send it in a URL.
Given text of ‘I like fish for dinner’ the URL ends up looking like this:
https://api.idolondemand.com/1/api/sync/analyzesentiment/v1?text=I+like+fish+for+dinner&apikey=0351acf2-ce16-4076-8ac2-3442556
The below code shows a standard method for requesting a URL and this is used for all the API endpoints.
private Response executeGet(String url) throws IOException {
HttpURLConnection httpUrlConnection = null;
InputStream inputStream;
try {
httpUrlConnection = (HttpURLConnection) new URL(url).openConnection();
httpUrlConnection.setReadTimeout(20 * 1000);
httpUrlConnection.connect();
inputStream = httpUrlConnection.getResponseCode() != HTTP_OK ? httpUrlConnection.getErrorStream()
: httpUrlConnection.getInputStream();
return new Response(httpUrlConnection.getResponseCode(), fromInputStream(inputStream));
} finally {
closeQuietly(httpUrlConnection);
}
}
The response that we receive is JSON formatted. To do anything useful with this we need to de-serialize it into a Java object. Jackson is a great library for easily doing this — it gets out of your way and doesn’t require mapping files/annotations.
We know what to expect from the response (from the docs) and here is the response for our ‘I like fish for dinner’ example:
{
"positive": [
{
"sentiment": "like",
"topic": "fish for dinner",
"score": 0.7176687736973063,
"original_text": "I like fish for dinner",
"original_length": 22,
"normalized_text": "I like fish for dinner",
"normalized_length": 22
}
],
"negative": [],
"aggregate": {
"sentiment": "positive",
"score": 0.7176687736973063
}
}
Pretty good analysis!
If we provide a java object that closely matches the structure of the JSON then Jackson can do the rest and we don’t have to write much code for the conversion. Here it is:
public class SentimentAnalysisResponse {
public SentimentAnalysisResponse(){}
private List<SentimentDetails> negative;
private List<SentimentDetails> positive;
private SentimentAggregate aggregate;
public SentimentAggregate getAggregate() {
return aggregate;
}
public void setAggregate(SentimentAggregate aggregate) {
this.aggregate = aggregate;
}
public List<SentimentDetails> getNegative() {
return negative;
}
public void setNegative(List<SentimentDetails> negative) {
this.negative = negative;
}
public List<SentimentDetails> getPositive() {
return positive;
}
public void setPositive(List<SentimentDetails> positive) {
this.positive = positive;
}
public static class SentimentAggregate {
private String sentiment;
private Double score;
public String getSentiment() {
return sentiment;
}
public void setSentiment(String sentiment) {
this.sentiment = sentiment;
}
public Double getScore() {
return score;
}
public void setScore(Double score) {
this.score = score;
}
}
public static class SentimentDetails {
public SentimentDetails(){}
public String getSentiment() {
return sentiment;
}
public void setSentiment(String sentiment) {
this.sentiment = sentiment;
}
private String sentiment;
private String topic;
private Double score;
private String normalized_text;
private String original_text;
private Integer original_length;
private Integer normalized_length;
public String getTopic() {
return topic;
}
public void setTopic(String topic) {
this.topic = topic;
}
public Double getScore() {
return score;
}
public void setScore(Double score) {
this.score = score;
}
public String getNormalized_text() {
return normalized_text;
}
public void setNormalized_text(String normalized_text) {
this.normalized_text = normalized_text;
}
public Integer getOriginal_length() {
return original_length;
}
public void setOriginal_length(Integer original_length) {
this.original_length = original_length;
}
public Integer getNormalized_length() {
return normalized_length;
}
public void setNormalized_length(Integer normalized_length) {
this.normalized_length = normalized_length;
}
public String getOriginal_text() {
return original_text;
}
public void setOriginal_text(String original_text) {
this.original_text = original_text;
}
}
}
Note that there is a default constructor (no args) for each object. This is required by Jackson due to the way it constructs objects. Our code to translate the JSON response to this object is
ObjectMapper mapper = new ObjectMapper();
JsonParser parse = new JsonFactory().createParser(response);
SentimentAnalysisResponse resp = mapper.readValue(parse,SentimentAnalysisResponse.class);
It should be clear what we are doing here. Putting it all together looks like this:
public SentimentAnalysisResponse analyseSentimentUsingText(String text, String language) {
SentimentAnalysisRequest.SentimentLanguage lang;
try{
lang = SentimentAnalysisRequest.SentimentLanguage.valueOf(language.toUpperCase());
} catch (IllegalArgumentException e){
lang = null;
}
SentimentAnalysisRequest req = new SentimentAnalysisRequest(
ProcessRequestType.TEXT, text, lang);
String urlComponent = req.toUrlComponent();
String response = null;
try {
response = executeGet(BASE_URL + "sync" + "/" + urlComponent + getApiUrlComponent()).content;
ObjectMapper mapper = new ObjectMapper();
JsonParser parse = new JsonFactory().createParser(response);
SentimentAnalysisResponse resp = mapper.readValue(parse,SentimentAnalysisResponse.class);
return resp;
} catch (JsonMappingException e){
logger.error("error encountered for response " + response + " with text " + text);
return null;
} catch (IOException e) {
logger.error("Exception encountered when trying to analyse sentiment",e);
return null;
}
}
This can be repeated for all of the API endpoints in a similar manner. Once I’ve written the calls for a few more endpoints I’ll publish it as a library.
I’m not going to concentrate on how to get the statuses from Twitter as that is out of scope but you can look at the code for this project <here>. We have a stream of tweets coming in to which we attach extra information from the IDOL API:
- The language of the tweet
- The sentiment analysis
- The tweet text with key terms from the sentiment analysis highlighted
These then get sent to a store where they are retrieved when requested from the front-end web page.
The web page is little more than a list of the enriched tweets. It uses JSP to obtain the list then Bootstrap to organise all the elements of the page.
A small bit of JavaScript allows us to see more details about the tweet and we are done! Here is a little GIF of the final version.
Conclusion
The HP IDOL API provides powerful analysis tools in an easy to use format. It can be combined with all sorts of unstructured data sources to create a useful tool in a small amount of time.



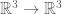 . Any vertices that are mapped to the cube bounded by
. Any vertices that are mapped to the cube bounded by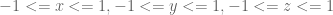
 is mapped to the above cube, i.e. we need to know the preimage of the cube so that we know where to place our vertices. We usually use two types of projection matrix which OpenGL provides by default.
is mapped to the above cube, i.e. we need to know the preimage of the cube so that we know where to place our vertices. We usually use two types of projection matrix which OpenGL provides by default.


